How do we build a DocSearch index?
In this section you will learn how we build a DocSearch index from your page.
Everything starts from your page

We extract the payload with to your set of selectors

We will focus on the highlighted information depending on your selectors.
We iterate through the HTML flow and build the payload
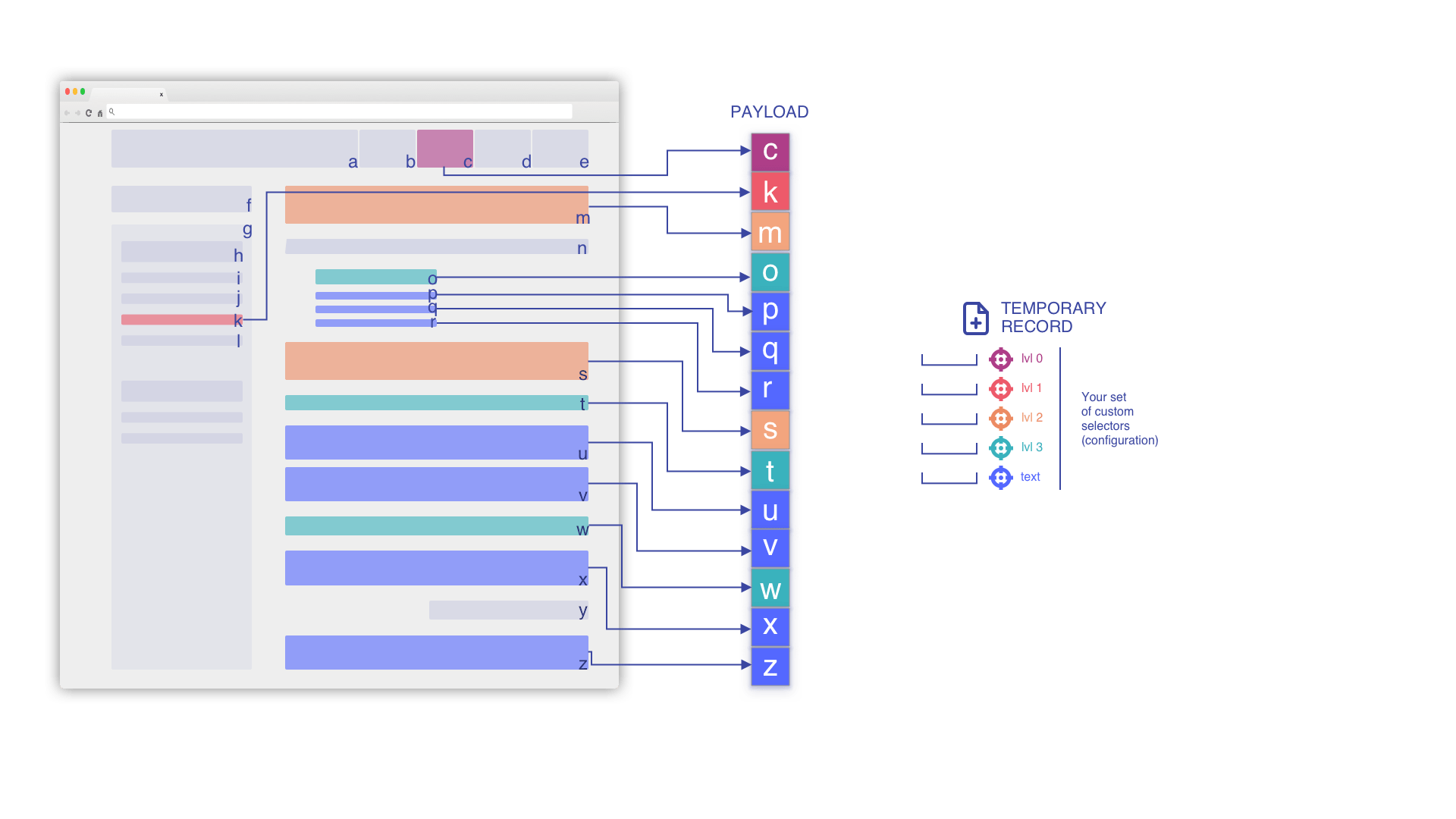
This payload will be the only data extracted from your page.
We iterate through the payload and start pushing records
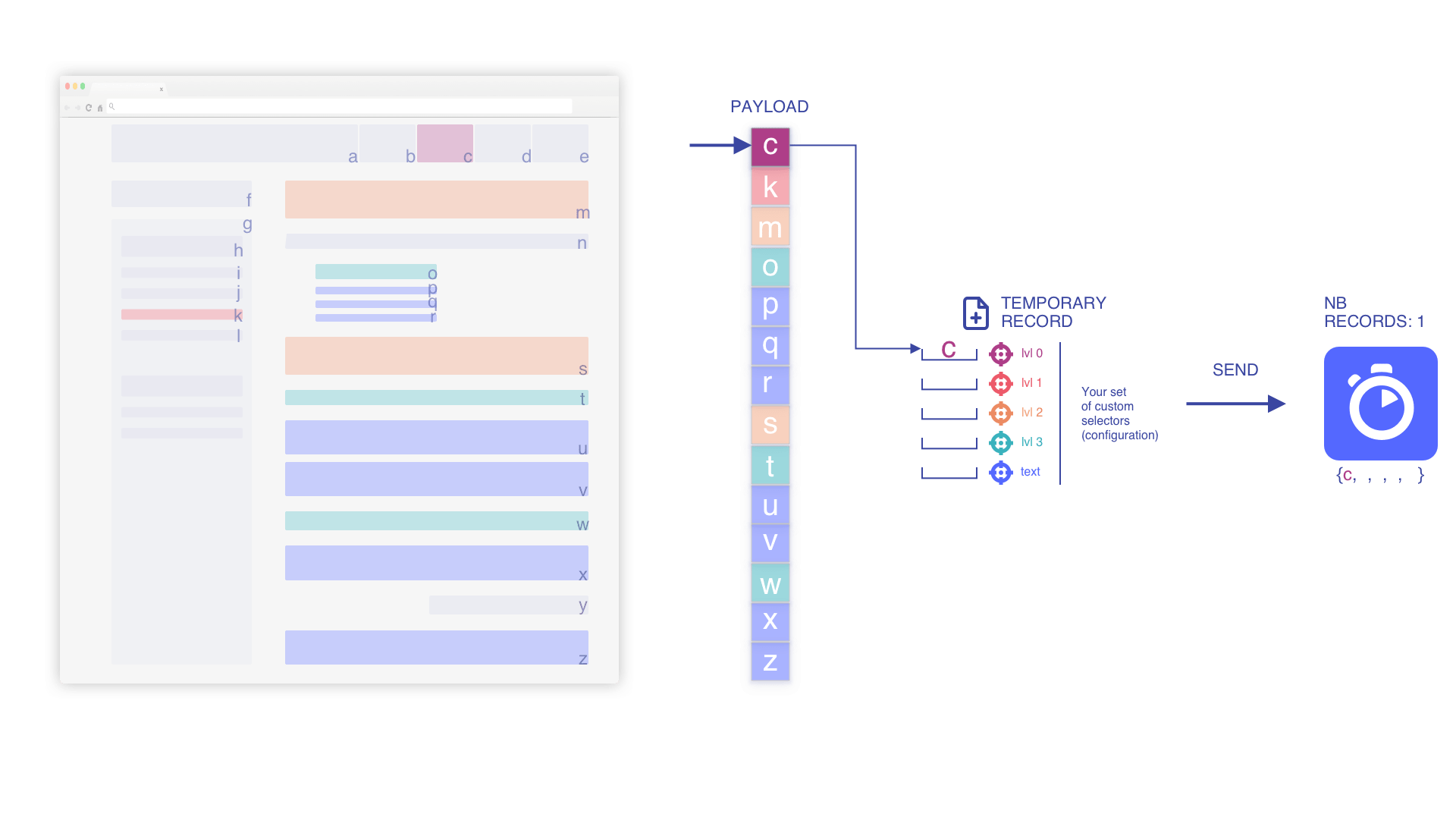
We index the temporary record when we add an element to it (if min_indexed_level equals 0)
We pile up the elements based on the current temporary record
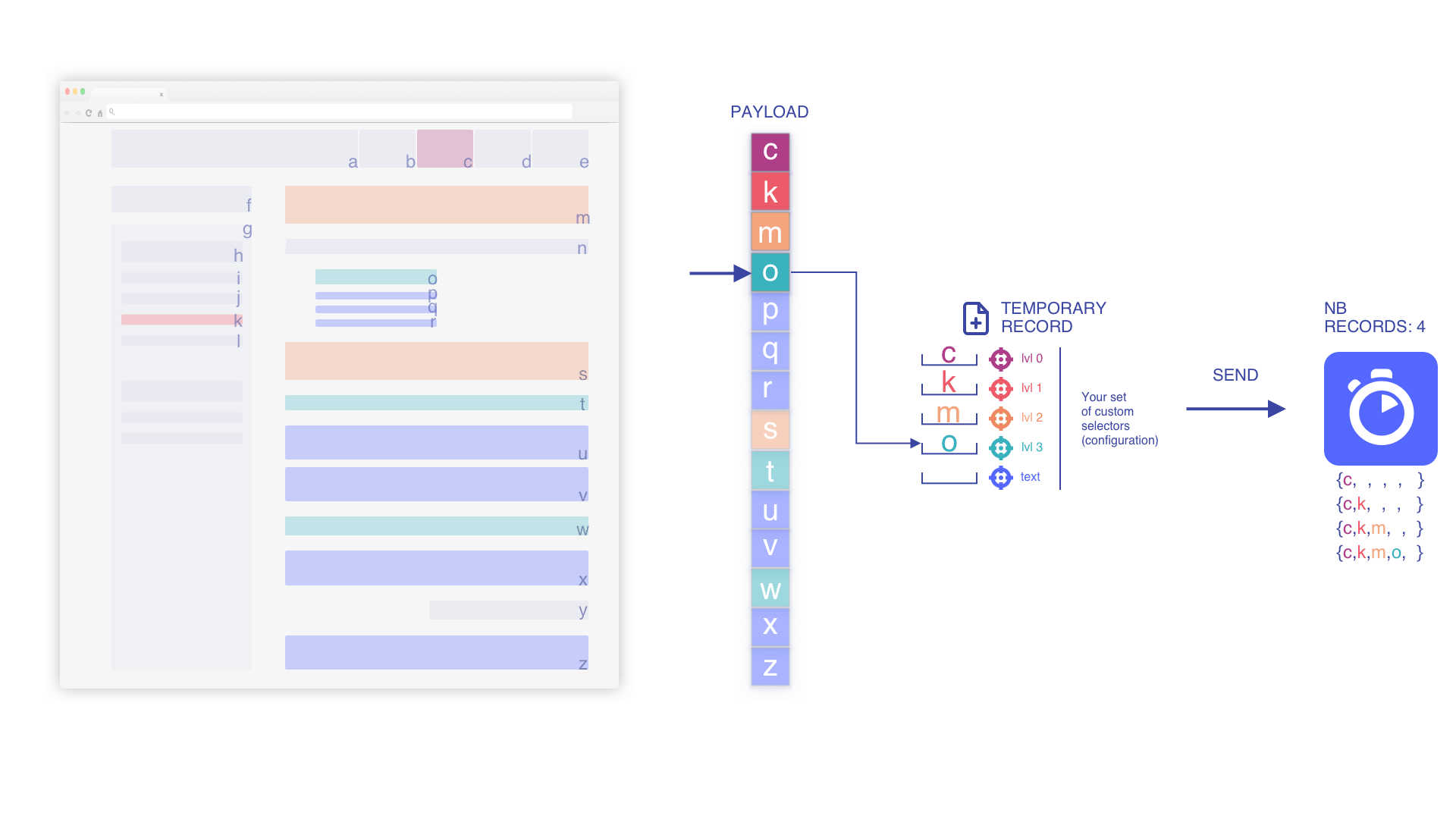
Based on the position within the flow, we nest elements as much as possible to keep the context and increase the relevancy.
We iterate until we match a text element
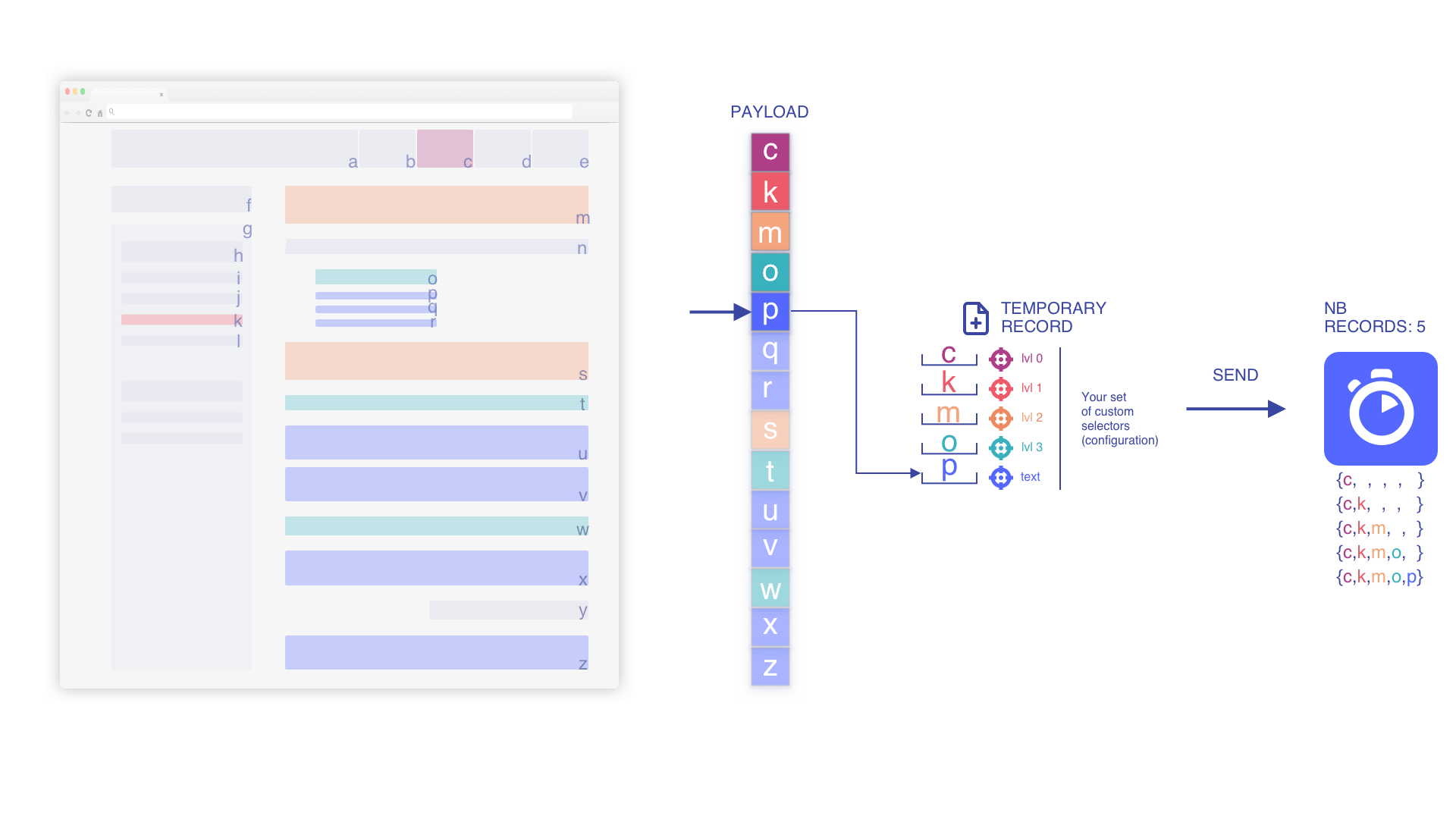
We override the text element when we find a newer one
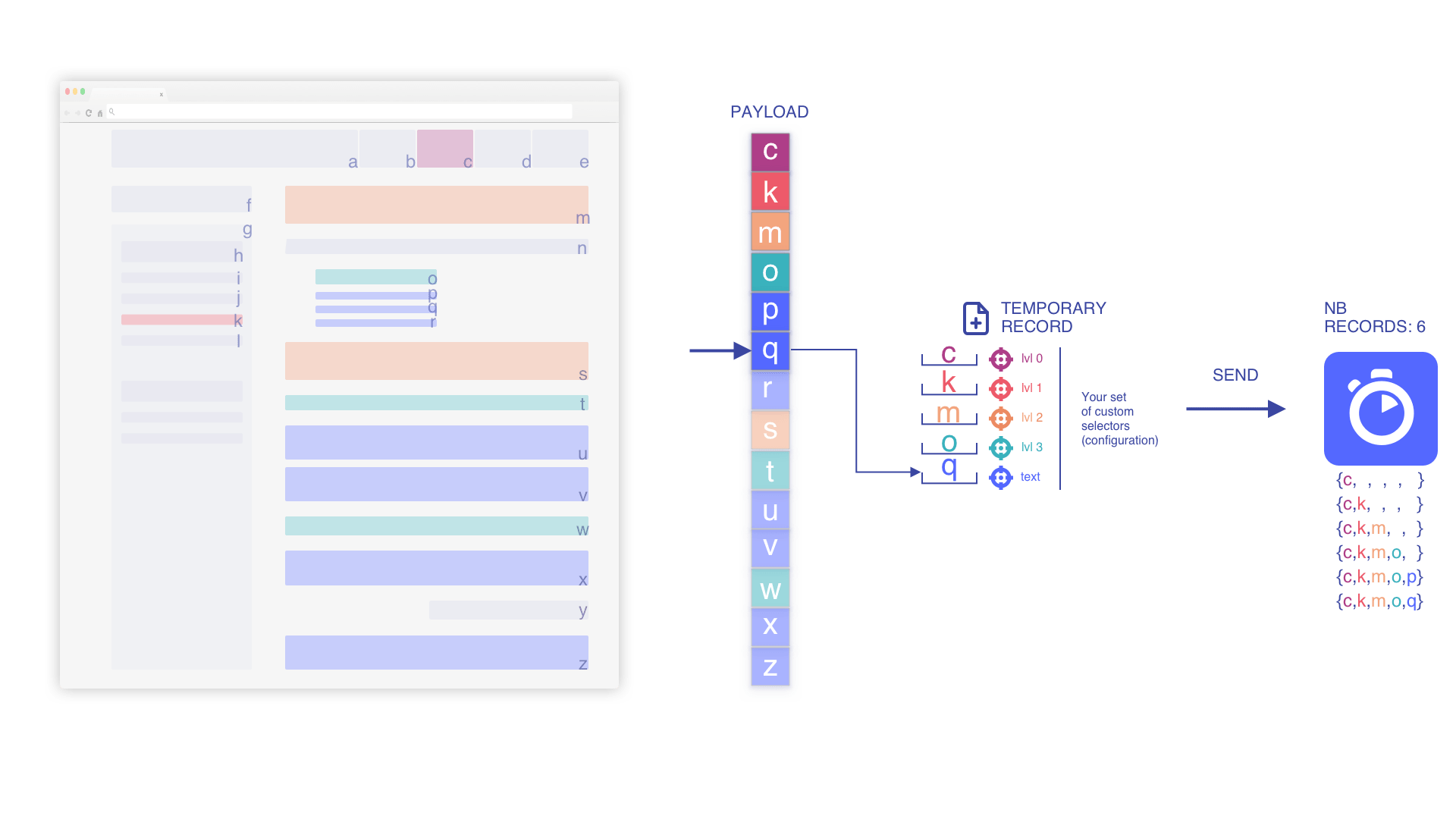
We remove the stashed, deeper elements when we add a higher level
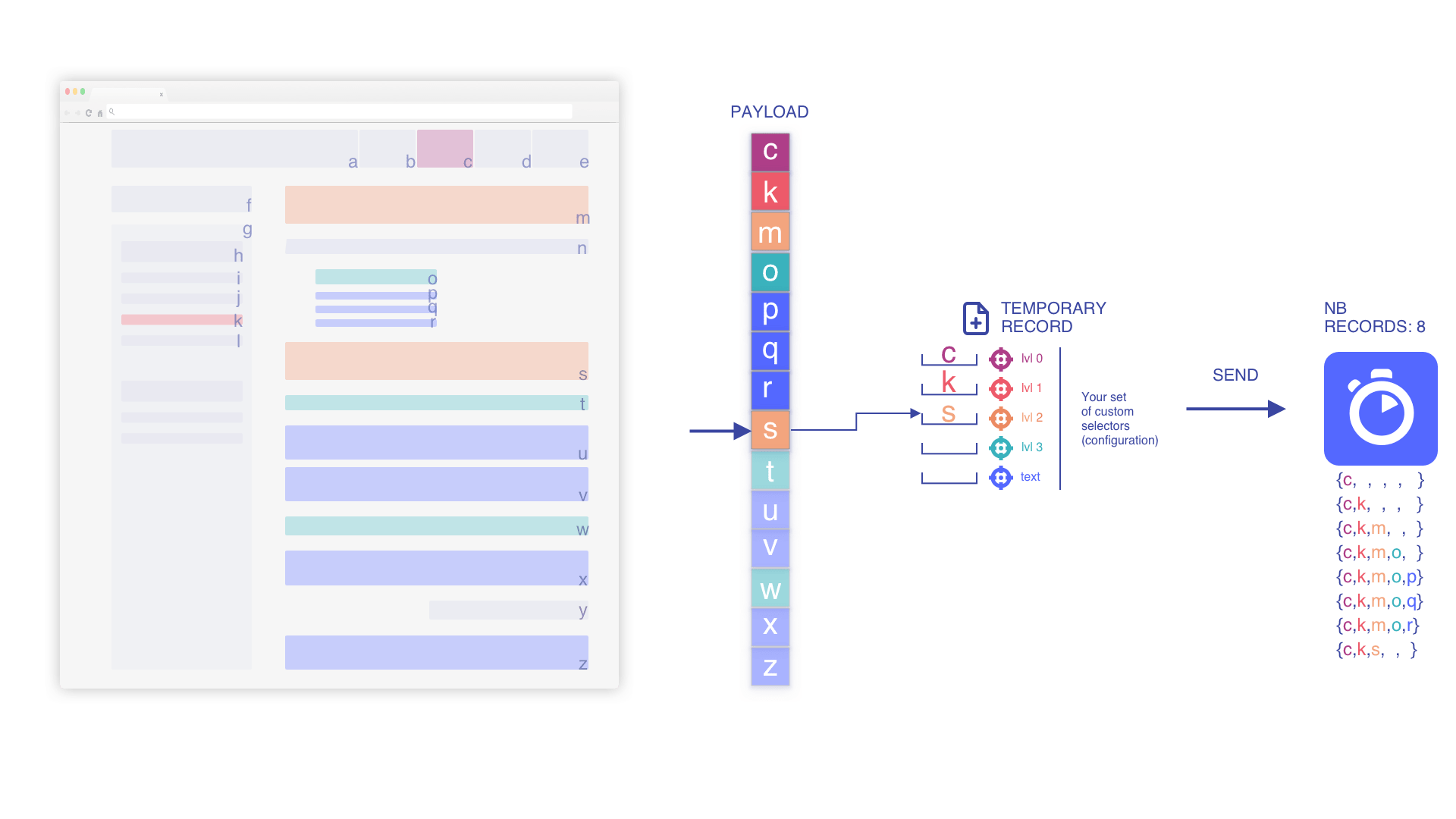
Contextual information and hierarchy must be updated once we encounter a new level. We are doing that because it highlights a new sub-section not related to the previous one.
If you need any further information, please contact us.